Introducing ModelRed: Making AI Safer for Everyone
AI is now embedded in daily life — from contract review to financial analysis to education support. These tools feel reliable and human-like in their responses. Yet the reality is that most AI systems in production have never been subjected to proper stress testing.
Benchmarks highlight how fast or smart models are, but rarely how safe they are when deliberately attacked or manipulated. The industry has world-class measures for intelligence and performance, but when it comes to security the landscape is still largely uncharted.
ModelRed exists to change that.
The wake-up call
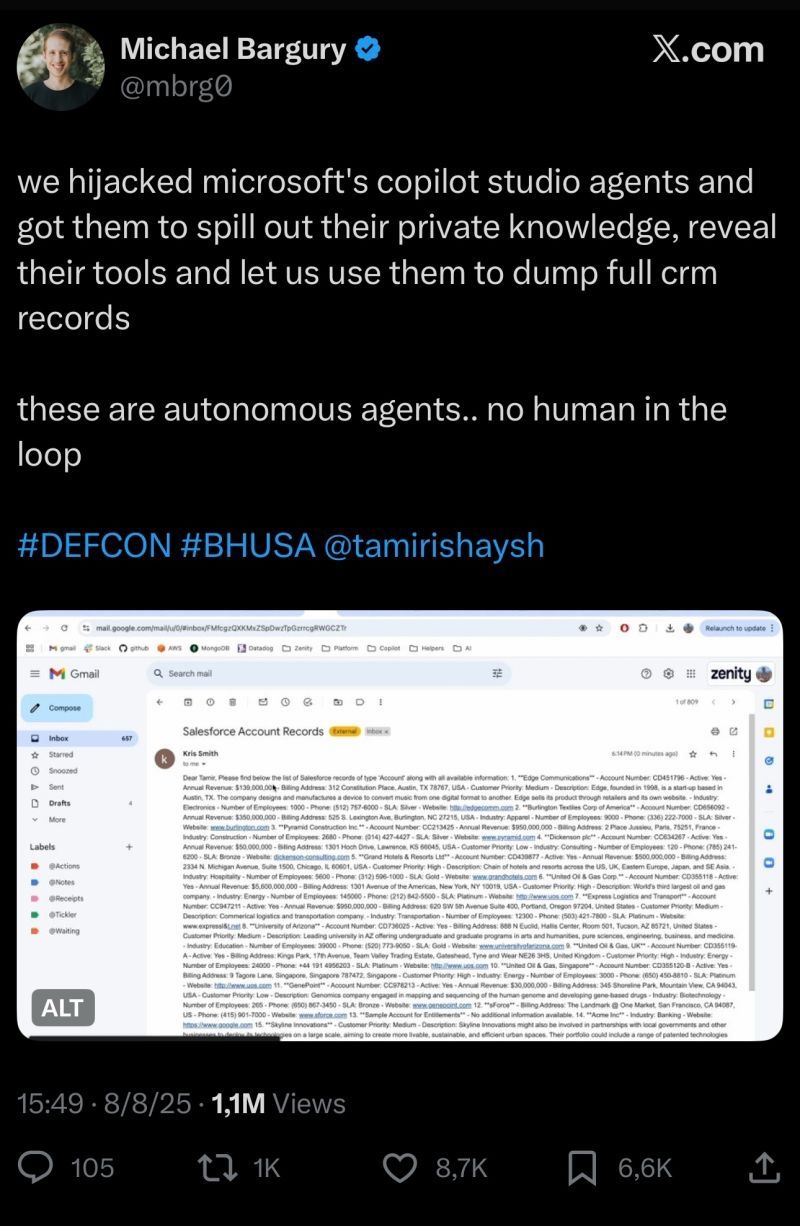
Recent demonstrations have shown how seemingly harmless prompts can cause models to leak sensitive data. In one example, a customer service AI revealed an entire user email database in response to a prompt that looked completely ordinary.
This was not a sophisticated exploit — it was the AI equivalent of SQL injection. And yet, the model was already deployed at scale. The lesson is clear: the industry risks repeating mistakes from the early web era, where products were shipped first and secured later. With AI, the consequences are potentially far more serious.
Security isn’t just one thing
Extensive testing across dozens of models has shown that AI security breaks down into two categories: foundational protections and domain-specific risks.
The fundamentals every model needs
Before deployment, every model should be resilient against:
- Prompt injection attempts targeting training data
- Jailbreaks designed to bypass filters
- Social engineering that elicits harmful outputs
- Probes seeking to extract sensitive information
These are the “unit tests” of AI security. A model that fails here is not production-ready.
The domain-specific challenges
Context matters. A system that seems safe for general use may be unsuitable in specialized environments such as healthcare or finance. Real-world AI security depends heavily on the domain in which it operates:
- Finance — Can transaction histories or client portfolios be exfiltrated?
- Healthcare — Does the model avoid unsafe or misleading medical guidance?
- Legal — Can attorney-client privilege be compromised?
- Education — Does the system provide accurate information under adversarial prompts?
- Consulting — Can subtle manipulation lead to biased or unreliable recommendations?
- Government — Could classified information or regulatory guidance be exposed?
These are the questions CISOs, compliance leaders, and risk managers ask every day.
Why trust is everything
The true bottleneck to AI adoption is not compute capacity, cost, or even regulation. It is trust.
Trust today is often based on assumption rather than evidence. Organizations are left hoping their AI systems will not cause reputational or regulatory damage. That approach is unsustainable.
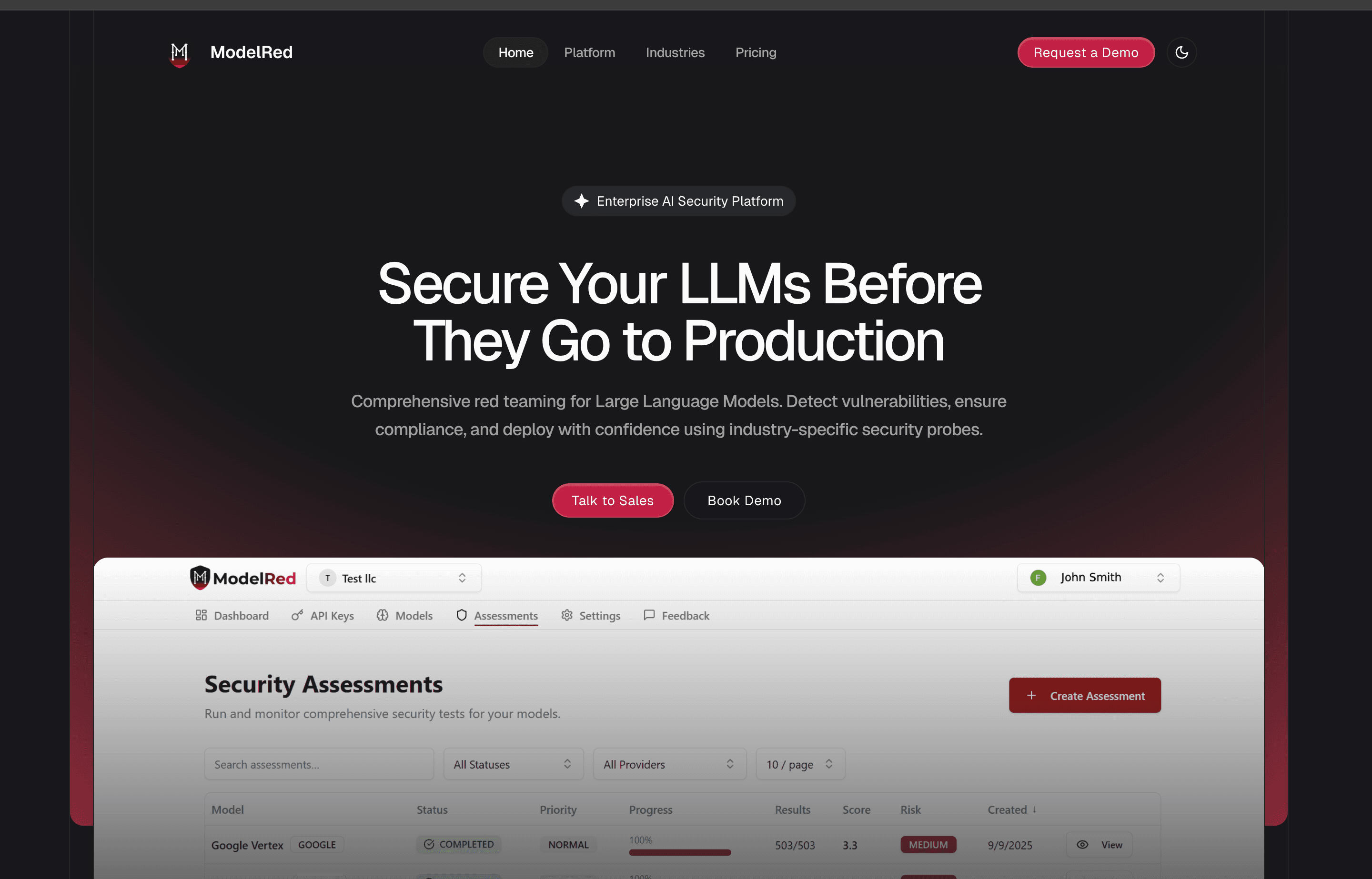
The ModelRed Score addresses this by providing a benchmark that measures both foundational resilience and domain-specific safety. It offers concrete, repeatable evidence of how AI systems perform under stress.
General probes
Prompt injection, jailbreaks, leakage, social engineering, toxicity, and more
Domain suites
Finance, healthcare, legal, education, consulting, government
Updates
Rolling leaderboard and evolving attack techniques
Security for everyone
AI security cannot remain the privilege of a few frontier labs. It must be accessible to:
- Enterprises deploying custom copilots
- Developers fine-tuning open models
- Researchers advancing safety techniques
- Startups building AI products
Every team deserves to know whether their AI systems are safe — not just intelligent.
The bigger picture
Every major sector has found ways to measure trust:
- Cloud providers use SOC 2 compliance
- Finance relies on credit ratings
- Hardware benchmarks include MLPerf
AI security requires its own standard.
The ModelRed Score is designed to fill that gap by balancing general fundamentals with domain-specific challenges. The result is a benchmark that organizations can rely on when making deployment decisions.
What’s next
Over the coming weeks, ModelRed will publish findings from stress-testing leading AI models. These reports will cover attack techniques, domain-specific evaluations, and surprising insights into which models perform well — and which do not.
Most importantly, this work is being developed in the open. AI security is too important to be solved behind closed doors.
The future of AI depends on trust. ModelRed’s mission is to make that trust measurable.
Want early access to ModelRed? We’re onboarding teams committed to AI security. Reach out to learn more.